Background
I've found myself trying to quantify differences between available data store options in .NET many times over the last decade. Historically I've performed such comparisons using a simple Console Application project in Visual Studio. I'd write test methods to provide comparable data for the data stores under evaluation, analyze the data, select for implementation and move forward. I've experienced success with this pattern for many years.
Recently, I found myself about to write code for yet another such comparison, once again I was re-inventing some testing methodologies. This time I decided to create (and document) an abstraction layer around the concept of a data store. My thinking was to provide a single testable abstraction that could be implemented in any .NET data storage technology. Not only would future tests be easier to write but the empirical data they generated would be standardized and thus comparable.
Objective
Design an abstraction layer in .NET which defines the concept of a "data store" then implement this abstraction using an array of .NET data storage technologies. Gather data. Compare and contrast results.
Source Code
DataRepositoryComparison is a Visual Studio solution targeting .NET 4.6.1. It contains the projects Model (Class Library), ConsoleApp (Console Application) and multiple separate data store implementation projects, e.g. Sql.Dapper. The Model project defines the common domain model abstractions to be used by all concrete implementations. ConsoleApp provides a run-time environment for testing. All other projects are specific implementations of the Model project's abstractions using a particular .NET data store technology, e.g. Dapper.
The Repository pattern is employed and an abstraction of the "data store" concept is defined.
public interface IRepository
{
bool Create(IEnumerable<IThing> things);
bool Delete(IEnumerable<string> ids);
IThing[] Get();
IThing[] Get(IEnumerable<string> ids);
}
This design allows for the creation of IThing entities, deletion of IThing entities by identifier, retrieval of all available IThing entities and retrieval of IThing entities by identifier. Note, IRepository has no metaphor for query (excluding by identifier) or update.
Setup
All testing was performed using the following Azure VM (Resource Manger deployment model).
- Template: SQL Server 2016 SP1 Standard on Windows Server 2016
- Size: DS2_V2 (2 Core, 7 GB, $104.16/month)
- Disk Type: SSD
The following IRepository implementations and their associated configurations were used to gather data.
Sql.Dapper: Local (VM) SQL ServerSql.Dapper: Azure SQL, Basic (5 DTU), $5/monthSql.Dapper: Azure SQL, Premium (125 DTU), $465/monthDocumentDB: 400 RU, $24/month/collectionDocumentDB: 10,000 RU, $600/month/collectionAzureStorageTable: Premium Account, LRSAzureStorageBlob: Premium Account, LRS
Method
The following is a simplified version of the data gathering cycle applied to each IRepository implementation.
IRepository repository = {concrete_implementation_instance};
IThing[] things = {GenFu_IThing_data};
repository.Create(things);
ids = repository.Get().Select(t => t.Id).ToArray();
repository.Get(ids);
repository.Delete(ids);
Timers were scoped around each IRepository method call and completion times were recorded.
For each IRepository implementation data was gathered using 100 iterations of the cycle each with 100 randomly generated IThing entities (thank you GenFu). Additionally, data gathering cycles were executed both synchronously and asynchronously.
Results
Discussion
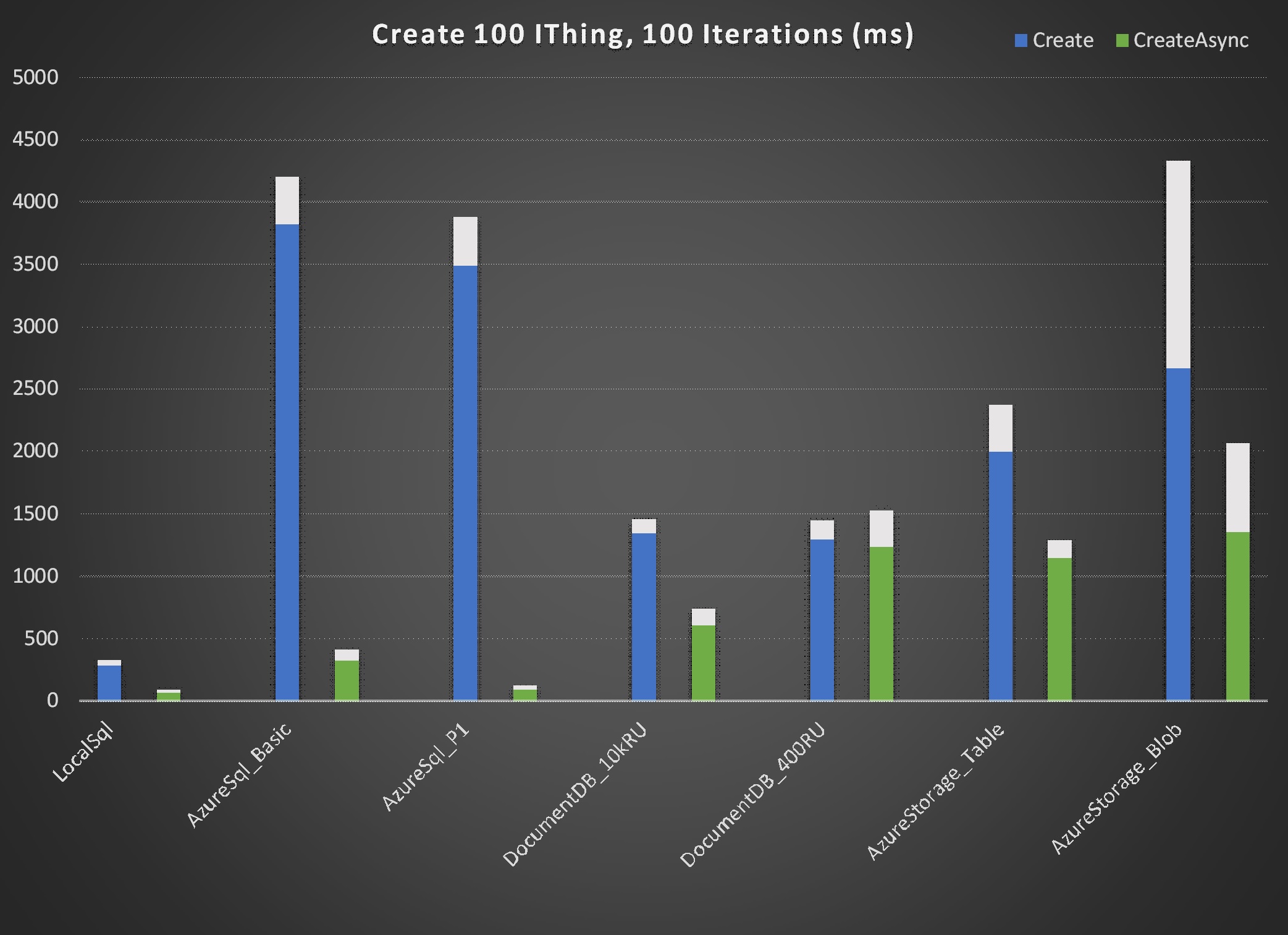
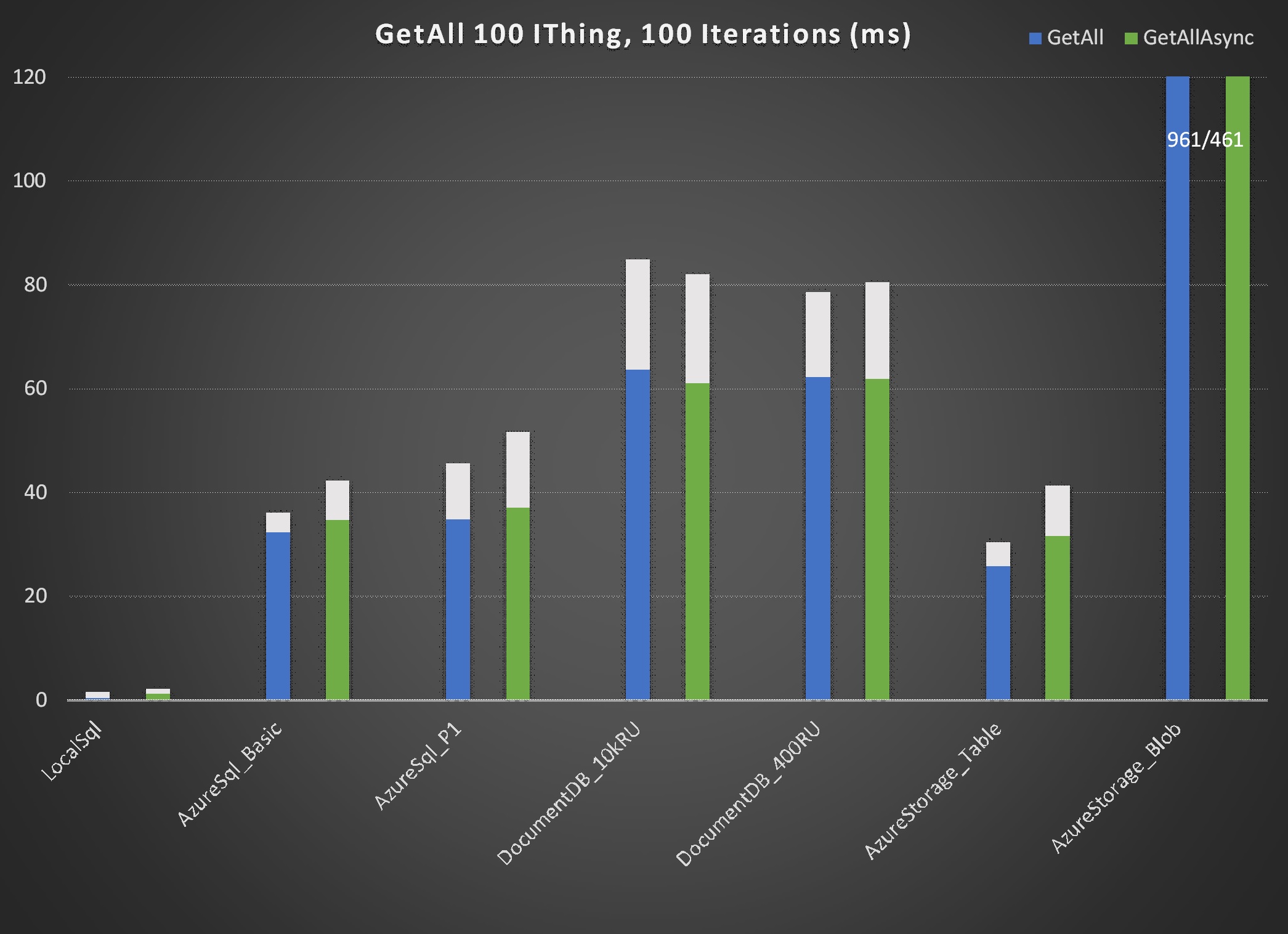
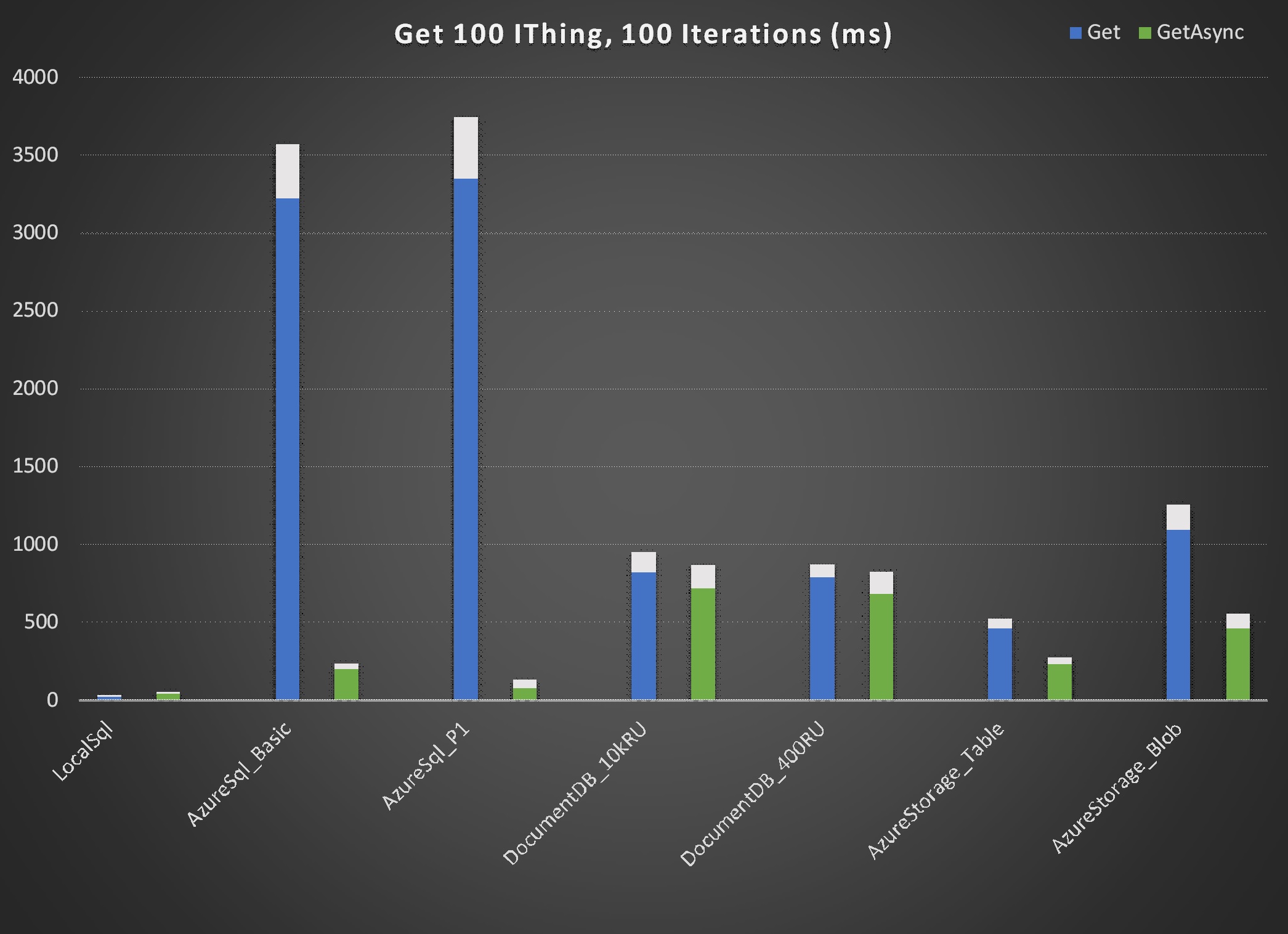
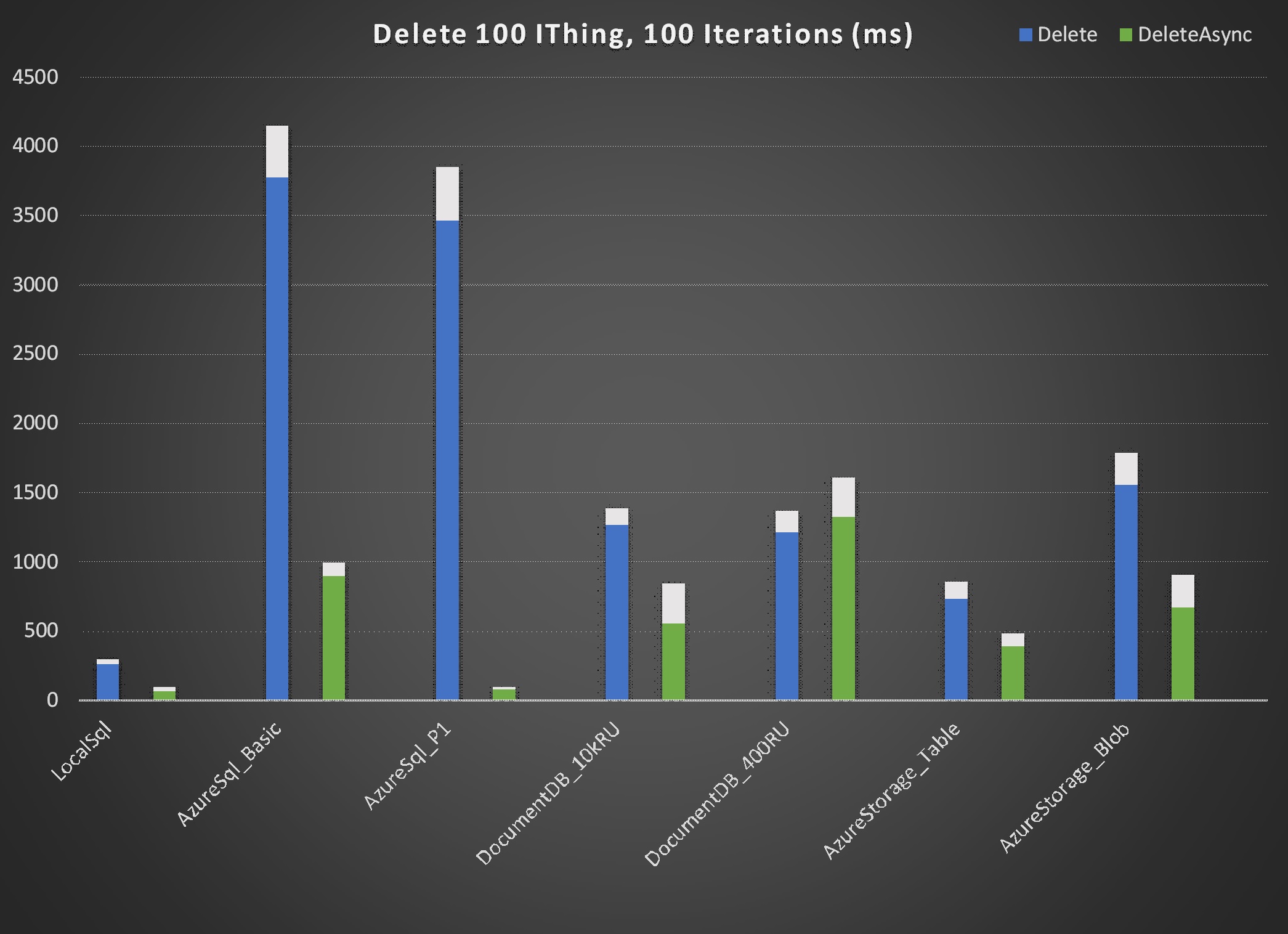
The "LocalSql" repository shown in the charts (Sql.Dapper implementation of IRepository on VM local resources) serves as an excellent baseline for comparisons. As expected "local" repository times for all actions are faster than those of other repositories. Most are significantly faster.
In almost every case asynchronous operations outperformed their synchronous counterparts. However, for Sql.Dapper Azure SQL the differences were dramatic in operations executed with unique Id, i.e. Create, Get, Delete. Note that for the remaining operation, i.e. GetAll, synchronous actually slightly outperformed asynchronous. The data suggests that Azure SQL is heavily optimized for asynchronous operations. That's consistent with expectations.
Excluding synchronous operations Sql.Dapper on Azure SQL made a strong showing. Even the Azure Basic tier database performs near the top of every operation. Also noteworthy is the performance of AzureStorageTable, again near the top in performance for each operation. A surprise for me was AzureStorageBlob. This implementation literally just serializes each IThing to json and writes it to an individual file on Azure Blob Storage. That would seem to be a horribly inefficient way to store data but, with the exception of GetAll, the performance is admirable.
Conclusions
The abstraction IRepository worked well with implementations of a widely varied group of data storage technologies. Implementations were simple to write and data gathered from exercising them was easily comparable. I'm satisfied with the results and will likely add additional implementations in the future.